TCP协议
TCP是一个非常复杂的协议,网络编程中要用到很多TCP的知识,更好的理解TCP有利于分析程序运行,发现问题,掌握TCP协议是一个网络编程人员的必备技能。
网络报头
TCP格式如下:
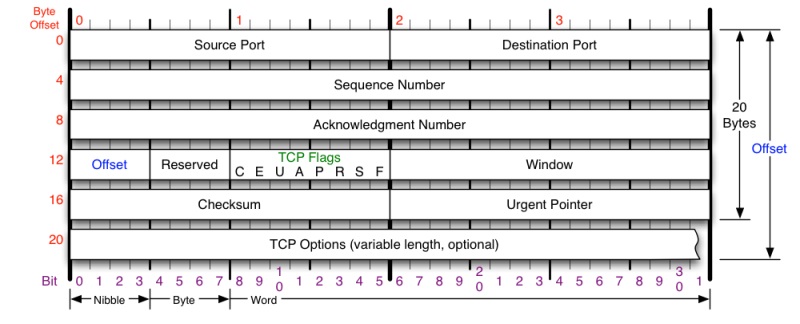 注意
注意
- 一个TCP连接需要四个元组来表示是同一个连接(src_ip, src_port, dst_ip, dst_port),IP地址在IP层已经制定,此处TCP层只需要端口号信息。
- Sequence Number是包的序号,用来解决网络包乱序(reordering)问题。Acknowledgement Number就是ACK——用于确认收到,用来解决不丢包的问题。 Window又叫Advertised-Window,也就是著名的滑动窗口(Sliding Window),用于解决流控的。
- TCP Flag ,也就是包的类型,主要是用于操控TCP的状态机的。
解释请看下图:
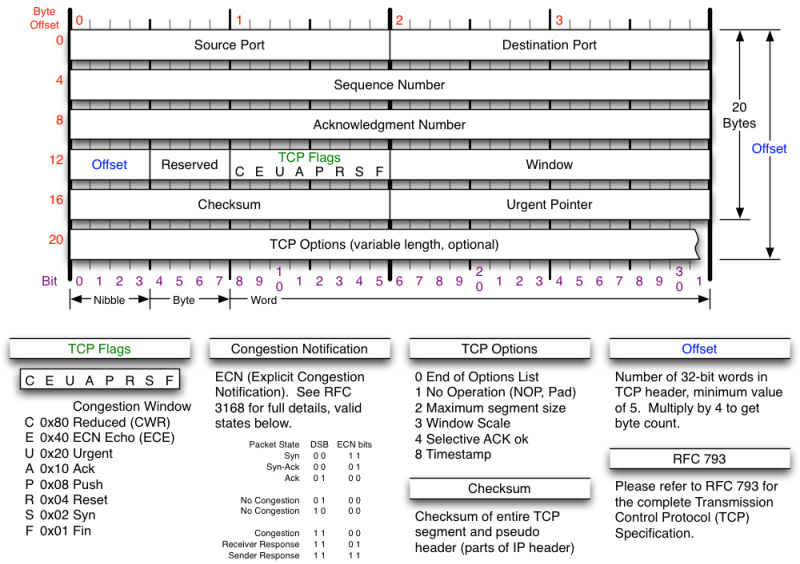
TCP的状态转换
TCP状态主要发生在三个地方:连接建立、收发数据和连接关闭。
首先看看TCP的状态转换图,连接关闭是状态变化非常的复杂:
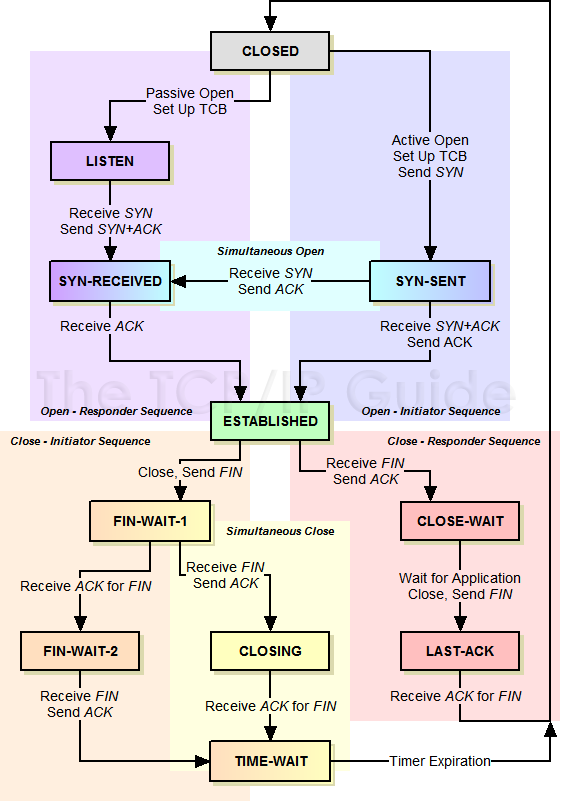
报文交换图:
关闭时需要4次挥手是因为TCP是全双工的,关闭一端就需要2次交互。
注意
- 同时关闭和同时建立连接是非常特殊的情况,TCP也能够正确处理。由于在实际中很少发生这种情况,暂且不做介绍。
- ISN是不能hard code的,不然会出问题的。RFC793中说,ISN会和一个假的时钟绑在一起,这个时钟会在每4微秒对ISN做加一操作,直到超过2^32,又从0开始。这样,一个ISN的周期大约是4.55个小时。因为,我们假设我们的TCP Segment在网络上的存活时间不会超过Maximum Segment Lifetime。
- TIME_WAIT状态:1)TIME_WAIT确保有足够的时间让对端收到了ACK,如果被动关闭的那方没有收到Ack,就会触发被动端重发Fin,一来一去正好2个MSL,2)有足够的时间让这个连接不会跟后面的连接混在一起。
TCP的重传机制
。TCP协议要求在发送端每发送一个报文段,就启动一个定时器并等待确认信息;接收端成功接收新数据后返回确认信息。若在定时器超时(Timeout)前数据未能被确认,TCP就认为报文段中的数据已丢失或损坏,需要对报文段中的数据重新组织和重传。
TCP的RTT算法
从前面的TCP重传机制我们知道Timeout的设置对于重传非常重要。
- 设长了,重发就慢,丢了老半天才重发,没有效率,性能差;
- 设短了,会导致可能并没有丢就重发。于是重发的就快,会增加网络拥塞,导致更多的超时,更多的超时导致更多的重发。
而且,这个超时时间在不同的网络的情况下,根本没有办法设置一个死的值。只能动态地设置。 为了动态地设置,TCP引入了RTT——Round Trip Time,也就是一个数据包从发出去到回来的时间。这样发送端就大约知道需要多少的时间,从而可以方便地设置Timeout——RTO(Retransmission TimeOut),以让我们的重传机制更高效。
TCP的滑动窗口
TCP头里有一个字段叫Window,又叫Advertised-Window,这个字段是接收端告诉发送端自己还有多少缓冲区可以接收数据。于是发送端就可以根据这个接收端的处理能力来发送数据,而不会导致接收端处理不过来。
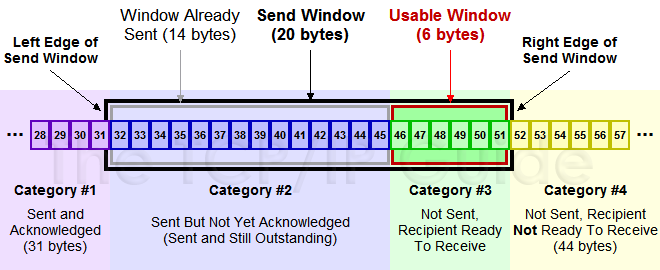
上图中分成了四个部分,分别是:(其中那个黑模型就是滑动窗口)
- #1已收到ack确认的数据。
- #2发还没收到ack的。
- #3在窗口中还没有发出的(接收方还有空间)。
- #4窗口以外的数据(接收方没空间)
注意 如果Window变成0了,TCP会怎么样? TCP使用了Zero Window Probe技术,缩写为ZWP,也就是说,发送端在窗口变成0后,会发ZWP的包给接收方,让接收方来ack他的Window尺寸,一般这个值会设置成3次,第次大约30-60秒(不同的实现可能会不一样)。如果3次过后还是0的话,有的TCP实现就会发RST把链接断了。
Silly Window Syndrome问题 Silly Windows Syndrome指的是报文中数据特别的少,只有几个字节,为了发送这几个字节,需要发送TCP+IP头有40个字节,这是一种特别浪费带宽的。这个现像就像是你本来可以坐200人的飞机里只做了一两个人。
TCP的拥塞处理 – Congestion Handling
拥塞控制主要是四个算法:1)慢启动,2)拥塞避免,3)拥塞发生,4)快速恢复。
慢热启动算法 – Slow Start
慢启动的算法如下(cwnd全称Congestion Window):
- 连接建好的开始先初始化cwnd = 1,表明可以传一个MSS大小的数据。
- 每当收到一个ACK,cwnd++; 呈线性上升。
- 每当过了一个RTT,cwnd每当过了一个RTT,cwnd = cwnd*2; 呈指数让升。
- 还有一个ssthresh(slow start threshold),是一个上限,当cwnd >= ssthresh时,就会进入“拥塞避免算法”
拥塞避免算法 – Congestion Avoidance
前面说过,还有一个ssthresh(slow start threshold),是一个上限,当cwnd >= ssthresh时,就会进入“拥塞避免算法”。一般来说ssthresh的值是65535,单位是字节,当cwnd达到这个值时后,算法如下:
- 收到一个ACK时,cwnd = cwnd + 1/cwnd
- 当每过一个RTT时,cwnd = cwnd + 1
这样就可以避免增长过快导致网络拥塞,慢慢的增加调整到网络的最佳值。很明显,是一个线性上升的算法。
拥塞状态时的算法
超时时的算法如下:
- 把ssthresh降低为cwnd值的一半
- 把cwnd重新设置为1
- 重新进入慢启动过程。
收到3个相同的ACK时的算法如下:
- 把ssthresh设置为cwnd的一半
- 把cwnd再设置为ssthresh的值(具体实现有些为ssthresh+3)
- 重新进入拥塞避免阶段。
快速恢复算法 – Fast Recovery
Fast Recovery算法如下:
- cwnd = sshthresh + 3 * MSS (3的意思是确认有3个数据包被收到了)
- 重传Duplicated ACKs指定的数据包
- 如果再收到 duplicated Acks,那么cwnd = cwnd +1
- 如果收到了新的Ack,那么,cwnd = sshthresh ,然后就进入了拥塞避免的算法了。